Richard is a committer on StormCrawler, CrawlerCommons and other open source projects such as Apache TomEE. He is a PhD student in the field of medical web data mining. His recent work “Crawling the German Health Web” was published in the Journal of Medical Internet Research and is about using StormCrawler as a focused web crawler to collect a large sample of the German Health Web.
Richard will now tell us about his experimentation with URLFrontier and crawler4j. As you probably know, URLFrontier is a project sponsored by the NLNet foundation that we, at DigitalPebble, have been working on for just over a year and it is now in its second iteration. Let’s start by explaining what it is all about…
What is URLFrontier?
Web crawlers need to store the information about the URLs they process, this is called a crawl frontier. Typically, each web crawling software has its own way of implementing this. Our very own StormCrawler is no exception, except that it is not tied to one specific backend but can use several implementations like Elasticsearch, SOLR or SQL.
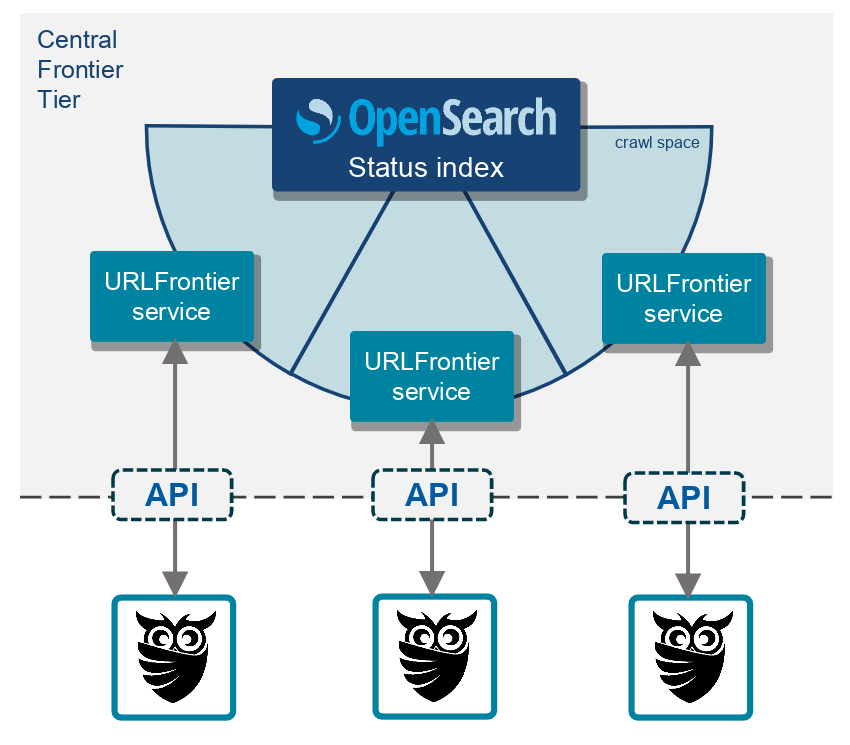
What URLFrontier does is to provide a crawler/language-neutral API for the operations that web crawlers do when communicating with a crawl frontier e.g. get the next URLs to crawl, update the information about URLs already processed, change the crawl rate for a particular hostname, get the list of active hosts, get statistics, etc...
URLFrontier is based on gRPC and provides not only an API but also an implementation of the service and client code in Java that can be used to communicate with it. Because the API and implementations are based on gRPC, URLFrontier can be used by web crawlers regardless of the programming language they are written in. As you would expect, StormCrawler has a module for URLFrontier, which was used extensively last year in a large-scale crawl described here.
By externalising the frontier logic from web crawlers, we can reuse the same implementation across different web crawlers and can make it better as a community instead of having each crawler project constantly reinventing the wheel. It also helps modularizing a crawler setup and make it distributed.
Let’s now see what Richard has been up to.
The crawler4j framework
Crawler4j is an open source web crawler written in Java, which provides a simple interface for crawling the Web in a single process. Sadly, the original (academic) project became mostly inactive with its last release in 2018 leaving users only two options: (1) migrate to another crawler framework or (2) maintain a fork of the library and release it to Maven Central. In the end, we decided to do the latter and forked the repository to continue using crawler4j within our academic research projects.
As setting up a multi-threaded web crawler with crawler4j is fairly simple, using a fully distributed web crawler would have been overkill for our small use-cases (i.e. focus on fetching single web sites). Therefore, we decided to maintain our own fork with up-to-date libraries and the possibility to (easily) switch between different frontier implementations as Oracle’s Sleepycat licence does not comply with some of our use-cases.
To start with crawler4j, you need to choose from one of the available crawl frontier implementations:
The HSQLDB and URLFrontier frontier implementations are only available in our fork. They aim to mitigate the rather strict licensing policies of Sleepycat.
After choosing a crawl frontier implementation, you can simply add the required dependency via Maven to your project (here: we choose URLFrontier):
<dependency>
<groupId>de.hs-heilbronn.mi</groupId>
<artifactId>crawler4j-with-urlfrontier</artifactId>
<version>4.8.2</version>
<type>pom</type>
</dependency>
Next, you have to create a crawler class which extends WebCrawler. This class decides which URLs should be crawled and handles the fetched web pages.
public class FrontierWebCrawler extends WebCrawler {
@Override
public boolean shouldVisit(Page referringPage, WebURL url) {
// determines, if a given URL should be visited by the crawler
return true
}
@Override
public void visit(Page page) {
//handle a fetched page, e.g. store it
}
}
In addition, you need to implement a controller class which specifies the seeds for the web crawl, the folder in which crawler4j will store intermediate crawl data and some other config options such as the number of crawler threads or if the web crawler should be polite and/or honour the robots exclusion protocol. This can be done like this:
protected CrawlController init() throws Exception {
final CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(“/tmp”);
config.setPolitenessDelay(800);
config.setMaxDepthOfCrawling(3);
config.setIncludeBinaryContentInCrawling(false);
config.setResumableCrawling(true);
config.setHaltOnError(false);
final BasicURLNormalizer normalizer = BasicURLNormalizer.newBuilder().idnNormalization(BasicURLNormalizer.IdnNormalization.NONE).build();
final PageFetcher pageFetcher = new PageFetcher(config, normalizer);
final RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
robotstxtConfig.setSkipCheckForSeeds(true); // we skip the robots checks for adding seeds (will be checked later on demand)
final int maxQueues = 10;
final int port = 10;
final FrontierConfiguration frontierConfiguration = new URLFrontierConfiguration(config, maxQueues, "localhost", port);
final RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher, frontierConfiguration.getWebURLFactory());
return new CrawlController(config, normalizer, pageFetcher, robotstxtServer, frontierConfiguration);
}
Seeds can then be added via the CrawlController. To increase performance, you can skip the robots.txt check while adding new seeds.
Crawler4j in ♥ with URLFrontier
The integration of URLFrontier in crawler4j basically boils down to three (adapter) classes and some boilerplate code to connect with the gRPC code provided by URLFrontier. This reduces the amount of crawler logic to handle the crawl frontier significantly.
As URLFrontier handles duplicate URLs and acts as a remote crawl frontier, it is now fairly simple to run crawler4j on different machines. URLFrontier then acts as the single point of synchronisation. Consequently, this approach can turn crawler4j into a simple distributed web crawler. Without a remote frontier (like URLFrontier), we would have had to implement a custom distributed URLFrontier using a framework like Hazelcast in order to distribute crawler4j’s crawl frontier. In both cases, distributing crawler4j comes at the cost that we need to implement additional business logic to handle or store the fetched Web pages in a distributed way. Nevertheless, the ease to implement a web crawler with crawler4j outweighs this issue.
The default URLFrontier service implementation is based on RocksDB and it is publicly available as a Docker image.
Experimenting with different frontier implementations
For our experiment, we relied on three virtual machines (VMs). Each VM is equipped with 4 vCPU, 10GB of memory and is running on Ubuntu 20.04 LTS with latest OpenJDK 17. We used a seed list of 1M URLs generated from the site rankings computed by CommonCrawl.
Each Web crawl was started simultaneously on each VM and was run for an exact duration of 48 hours. We limited the crawling depth per URL to 3. URLFrontier was run as a docker container residing on the same VM as the crawler. Every 30 seconds, we checked the amount of processed (i.e. completed) URLs.
Note, that we did not apply any further processing of fetched Web pages as this wasn’t in the scope of our experiment. The example’s code is available on GitHub.
Results
On average, the crawler4j framework was capable of downloading up to 90 web pages per minute with a politeness delay of 800ms between each request to the same host. The detailed statistics are:
Sleepycat: fetched ~ 90 pages / min;
URLFrontier: fetched ~ 72 pages / min;
HSQLDB: fetched: ~ 68 pages / min;
Figure 1 depicts the number of processed (i.e. fetched) URLs over the time period of 48 hours.

Overall, there is a noticeable difference between Sleepycat, URLFrontier and the HSQLDB frontier implementation. However, HSQLDB is only a few pages slower than the URLFrontier implementation. As can be seen from the aggregate numbers, Sleepycat is faster compared to the other implementations. We can assume that the proprietary Sleepycat communication protocol outperforms gRPC (URLFrontier) and JDBC (HSQLDB) calls by not adding too much communication overhead.
Conclusion
Performance aside, one benefit of using StormCrawler is that the code needed to integrate it in crawler4j boils down two only three classes while the other two implementations required a significantly more complex integration.
In addition, by adopting URLFrontier as a backend, it is possible to easily exchange the crawler implementation and re-use the same data as before. We also benefit from any improvements to the service implementation without the need to change a single line of code. In particular, the forthcoming versions of URLFrontier should contain some very useful features.
Another important advantage of URLFrontier is that it opens the content of the frontier to the outside world: You can manipulate or view the content of the frontier during an ongoing web crawl via the CLI. This is not possible for the other frontier implementations.
Overall, our experiment showed that URLFrontier is slower than the original Sleepycat implementation, which most likely originates from the overhead introduced by the gRPC calls to communicate with URLFrontier. This is also true for the JDBC-based HSQLDB implementation. On the plus side, URLFrontier does not suffer from (commercial) licensing issues such as Sleepycat and can turn crawler4j into a simple distributed web crawler with little additional work, unlike using the other two implementations.
The figures given in this post depend on the particular seed list, the ordering of URLs, and the hardware used for the experiment. Therefore, you might get different results for your specific use case. The resources and configurations of this experiment being publicly available, you can try to reproduce it and extend it as you wish.
Next steps
This experiment has been very successful and informative and we are hoping to run more benchmarks in the future, like for instance a larger scale crawling in fully distributed mode.
URLFrontier is getting many improvements in its current phase of development and we are beginning to see alternative implementations of the service, like this one based on Opensearch. We are also seeing the project gain some traction with existing web crawlers.
An alternative experiment would be to compare the performance of the different URLFrontier service implementations available. Exciting times ahead!
Happy crawling everyone and a massive thank you to Richard for being our guest writer.