
It has been a while since our first “Meet the StormCrawler users” blog and since StormCrawler is still going strong and used by a wide variety of users, we are delighted to put the spotlight on one of the most exciting projects that uses it. Our guests today are Michael Dinzinger and Saber Zerhoudi, both from the University of Passau in Germany.


Can you please introduce yourselves and the project you are working on?
Hello, we are Saber and Michael, both PhD students in Passau. Since September 2022, we have been working on OpenWebSearch.eu, a European research project, in which people from now more than 15 participating institutes collaborate on building an Open Web Index.
Our task here at Uni Passau is the collaborative and resource-efficient crawling, which is the first technical step in building the Index (see figure below). The end result are Metadata and Index files, currently in Parquet and CIFF format. These are hosted on the project partners’ shared infrastructure and will soon be available for download.

How do you use StormCrawler and URLFrontier?
We use StormCrawler to build our own crawling pipelines by configuring - and in some cases extending - the already existing software components. We particularly appreciate its high customizability, because we use the framework for classic discovery crawling, which we need to feed the Open Web Index, and also for more task-specific and research-oriented crawling.
A major challenge in our work is the heterogeneous infrastructure, on top of which we are building the crawling system. The different infrastructure partners in the project provide a large set of commodity hardware, which is hosted across different datacenters and dispersed over Europe. Despite the geographic distribution of the machines, all nodes should collaborate on the same shared crawl. For that purpose, we deploy URLFrontier in a central computing site. The Frontier services distribute the crawl space and communicate with the remote crawlers in order to provide them with a continuous flow of URLs to be fetched (see figure below). URLFrontier can use different backends to store the data, we chose to use one leveraging another open source project, OpenSearch.
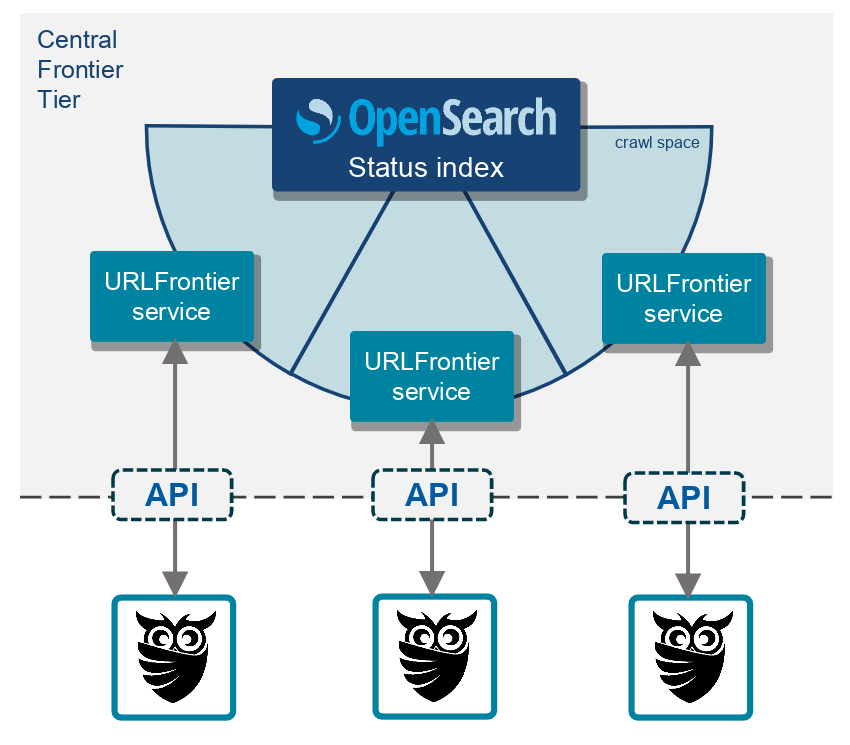
What results did you get so far?
The crawling is currently still in its experimental phase, but fortunately, we have already achieved some interesting and promising numbers. For example, we are running three StormCrawler instances at the moment. These have fetched over 200M web pages within a single week and each of them produced between 200 and 250 GiB of WARC files per day. The crawled data is filtered and enriched with meta information, before it is provided as index and metadata files to the public. In the next steps, we want to upscale the crawling to several terabytes and improve the prioritisation of crawl URLs to get a strong focus on high-quality pages.
It is definitely worth mentioning that the WARC module of StormCrawler helped us a lot. In order to get our indexing pipeline going, we started with copying WARC files from CommonCrawl, before we were able to crawl on our own.
Why did you choose StormCrawler?
We chose StormCrawler primarily for its compatibility with URLFrontier. This synergy made it an excellent starting point for developing a large-scale, coordinated, and distributed crawling cluster. Additionally, the open-source nature of the project and its active community influenced our decision. It was crucial for us to be supported by a network of developers who continuously enhance the core software and provide assistance or solutions when needed.
Did you make any contributions to it? Any advice you could give to future users and contributors?
Yes, we have contributed to StormCrawler by creating a forked version named OWLer.
This version includes several improvements and additions we deemed necessary for our project. We've implemented extended topologies for various purposes and added a classification component to categorise and annotate URLs based on either just the URL or the URL plus website content. It serves as a labelling tool for the crawler's content.
URLFrontier has also been expanded to accommodate these modifications, enabling crawlers to specialise in topics, languages, genres, etc.
Moreover, we have introduced a "Crawling-On-Demand" service. Users can register their requests on the new OWler webpage by specifying a list of seed URLs and additional information. Upon submission, a StormCrawler instance is deployed in our infrastructure, fetching and storing the content as WARC files in a dedicated S3 bucket. Once completed, users receive a link to download the WARC files via email. URLFrontier tracks the progress of these crawls.
What's next?
We are currently expanding our "Crawling-On-Demand" service to include "Indexing-On-Demand." Users will be able to specify a list of seed URLs and additional tags. We will then search our database of previously crawled and processed URLs for recent content matching this list and provide it to the user in an indexed format.
LinkedIn: openwebsearch-eu
X: OpenWebSearchEU
Mastodon: @openwebsearcheu@suma-ev.